mn create-app example.micronaut.micronautguide \
--features=graphql,data-jdbc,flyway,postgres,validation,graalvm \
--build=maven \
--lang=kotlin \
--test=junitTable of Contents
- 1. Getting Started
- 2. What you will need
- 3. Solution
- 4. Writing the Application
- 5. Persistence layer
- 6. GraphQL
- 7. Test Resources
- 8. Running the Application
- 9. Test the application
- 10. GraphiQL
- 11. Generate a Micronaut Application Native Executable with GraalVM
- 12. Next Steps
- 13. Help with the Micronaut Framework
- 14. License
Creating a ToDo application with Micronaut GraphQL
Build a TODO application with Micronaut GraphQL.
Authors: Sergio del Amo, Tim Yates
Micronaut Version: 4.10.9
1. Getting Started
In this guide, you will create a Micronaut application written in Kotlin that uses GraphQL to create a todo application.
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
You will be using:
-
A PostgreSQL instance provided by Test Resources and running in Docker.
-
Micronaut Data to persist our ToDos to this database.
-
Flyway to handle our database migrations.
-
Micronaut GraphQL to expose our data.
-
Testcontainers to run a PostgreSQL instance for local dev, and tests.
The application will expose a GraphQL endpoint at /graphql for the data to be consumed and modified.
2. What you will need
To complete this guide, you will need the following:
-
Some time on your hands
-
A decent text editor or IDE (e.g. IntelliJ IDEA)
-
JDK 21 or greater installed with
JAVA_HOMEconfigured appropriately
3. Solution
We recommend that you follow the instructions in the next sections and create the application step by step. However, you can go right to the completed example.
-
Download and unzip the source
4. Writing the Application
Create an application using the Micronaut Command Line Interface or with Micronaut Launch.
If you don’t specify the --build argument, Gradle with the Kotlin DSL is used as the build tool. If you don’t specify the --lang argument, Java is used as the language.If you don’t specify the --test argument, JUnit is used for Java and Kotlin, and Spock is used for Groovy.
|
The previous command creates a Micronaut application with the default package example.micronaut in a directory named micronautguide.
If you use Micronaut Launch, select Micronaut Application as application type and add graphql, data-jdbc, flyway, postgres, validation, and graalvm features.
| If you have an existing Micronaut application and want to add the functionality described here, you can view the dependency and configuration changes from the specified features, and apply those changes to your application. |
5. Persistence layer
5.1. Database Migration with Flyway
We need a way to create the database schema. For that, we use Micronaut integration with Flyway.
Flyway automates schema changes, significantly simplifying schema management tasks, such as migrating, rolling back, and reproducing in multiple environments.
Add the following snippet to include the necessary dependencies:
pom.xml
<dependency>
<groupId>io.micronaut.flyway</groupId>
<artifactId>micronaut-flyway</artifactId>
<scope>compile</scope>
</dependency>We will enable Flyway in the Micronaut configuration file and configure it to perform migrations on one of the defined data sources.
src/main/resources/application.properties
(1)
flyway.datasources.default.enabled=true| 1 | Enable Flyway for the default datasource. |
| Configuring multiple data sources is as simple as enabling Flyway for each one. You can also specify directories that will be used for migrating each data source. Review the Micronaut Flyway documentation for additional details. |
Flyway migration will be automatically triggered before your Micronaut application starts. Flyway will read migration commands in the resources/db/migration/ directory, execute them if necessary, and verify that the configured data source is consistent with them.
Create the following migration files with the database schema creation:
src/main/resources/db/migration/V1__schema.sql
CREATE TABLE author (1)
(
id BIGINT PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
username VARCHAR(255) NOT NULL
);
CREATE TABLE to_do (2)
(
id BIGINT PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
title VARCHAR(255) NOT NULL,
completed BOOLEAN NOT NULL,
author_id BIGINT REFERENCES author (id)
);| 1 | Authors will be stored in table separate to the ToDos. They just have a username. |
| 2 | ToDos have a title, completion status, and a foreign-key reference to the author. |
5.2. Entities
Create an Entity class to represent an Author:
src/main/kotlin/example/micronaut/Author.kt
package example.micronaut
import io.micronaut.data.annotation.GeneratedValue
import io.micronaut.data.annotation.GeneratedValue.Type.AUTO
import io.micronaut.data.annotation.Id
import io.micronaut.data.annotation.MappedEntity
import jakarta.validation.constraints.NotNull
@MappedEntity (1)
class Author(val username: @NotNull String?) {
@Id (2)
@GeneratedValue(AUTO)
var id: Long? = null
}| 1 | Annotate the class with @MappedEntity to map the class to the table defined in the schema. |
| 2 | Specifies the ID of an entity |
And another to represent a ToDo:
src/main/kotlin/example/micronaut/ToDo.kt
package example.micronaut
import io.micronaut.data.annotation.GeneratedValue
import io.micronaut.data.annotation.GeneratedValue.Type.AUTO
import io.micronaut.data.annotation.Id
import io.micronaut.data.annotation.MappedEntity
@MappedEntity (1)
class ToDo(var title: String, val authorId: Long) {
@Id (2)
@GeneratedValue(AUTO)
var id: Long? = null
var completed = false
}| 1 | Annotate the class with @MappedEntity to map the class to the table defined in the schema. |
| 2 | Specifies the ID of an entity |
5.3. Repositories
Create a JdbcRepository for each of our Entity classes.
The simplest of these is the ToDoRepository which just requires the default methods:
src/main/kotlin/example/micronaut/ToDoRepository.kt
package example.micronaut
import io.micronaut.data.jdbc.annotation.JdbcRepository
import io.micronaut.data.model.query.builder.sql.Dialect.POSTGRES
import io.micronaut.data.repository.PageableRepository
@JdbcRepository(dialect = POSTGRES) (1)
interface ToDoRepository : PageableRepository<ToDo, Long> (2)| 1 | @JdbcRepository with a specific dialect. |
| 2 | By extending CrudRepository you enable automatic generation of CRUD (Create, Read, Update, Delete) operations. |
Then create a Repository for the Authors. This requires extra finders for this to simplify the GraphQL wiring in the next step:
src/main/kotlin/example/micronaut/AuthorRepository.kt
package example.micronaut
import io.micronaut.data.jdbc.annotation.JdbcRepository
import io.micronaut.data.model.query.builder.sql.Dialect.POSTGRES
import io.micronaut.data.repository.CrudRepository
@JdbcRepository(dialect = POSTGRES) (1)
abstract class AuthorRepository : CrudRepository<Author, Long> { (2)
abstract fun findByUsername(username: String): Author? (3)
abstract fun findByIdIn(ids: Collection<Long>): Collection<Author> (4)
fun findOrCreate(username: String): Author { (5)
return findByUsername(username) ?: save(Author(username))
}
}| 1 | @JdbcRepository with a specific dialect. |
| 2 | By extending CrudRepository you enable automatic generation of CRUD (Create, Read, Update, Delete) operations. |
| 3 | When creating todos a method is required to search for an existing username. |
| 4 | When GraphQL loads a ToDo, it use this to fetch the authors if they are required in the response. |
| 5 | Find an existing author, or else create a new one when creating a ToDo. |
6. GraphQL
The initial Micronaut application create-app step already added the GraphQL dependency:
pom.xml
<dependency>
<groupId>io.micronaut.graphql</groupId>
<artifactId>micronaut-graphql</artifactId>
<scope>compile</scope>
</dependency>So the default GraphQL endpoint /graphql is enabled, and extra configuration is not required.
6.1. Describe your schema
Create the file schema.graphqls:
src/main/resources/schema.graphqls
type Query {
toDos: [ToDo!]! (1)
}
type Mutation {
createToDo(title: String!, author: String!): ToDo (2)
completeToDo(id: ID!): Boolean! (3)
}
type ToDo { (4)
id: ID!
title: String!
completed: Boolean!
author: Author!
}
type Author { (5)
id: ID!
username: String!
}| 1 | Declare a toDos query function to fetch all the todos as a list. |
| 2 | Declare a createToDo mutation function to create and return a new ToDo. |
| 3 | Declare a completeToDo mutation function to mark a ToDo as done (and return a boolean indicating success). |
| 4 | Declare a ToDo type. |
| 5 | Declare an Author type. |
6.2. Data Fetchers
For each query and mutator in the schema, create a DataFetcher which will bind the GraphQL schema to our domain model.
These will execute the appropriate queries in the datastore.
6.2.1. Queries
Create class ToDosDataFetcher to implement the toDos query:
src/main/kotlin/example/micronaut/ToDosDataFetcher.kt
package example.micronaut
import graphql.schema.DataFetcher
import graphql.schema.DataFetchingEnvironment
import jakarta.inject.Singleton
@Singleton (1)
class ToDosDataFetcher(
private val toDoRepository: ToDoRepository (2)
) : DataFetcher<Iterable<ToDo?>> {
override fun get(env: DataFetchingEnvironment): Iterable<ToDo?> {
return toDoRepository.findAll()
}
}| 1 | Use jakarta.inject.Singleton to designate a class as a singleton. |
| 2 | Use constructor injection to inject a bean of type ToDoRepository. |
6.2.2. Mutations
Create CreateToDoDataFetcher for the creation of ToDos:
src/main/kotlin/example/micronaut/CreateToDoDataFetcher.kt
package example.micronaut
import graphql.schema.DataFetcher
import graphql.schema.DataFetchingEnvironment
import jakarta.inject.Singleton
import jakarta.transaction.Transactional
@Singleton (1)
open class CreateToDoDataFetcher(
private val toDoRepository: ToDoRepository, (2)
private val authorRepository: AuthorRepository
) : DataFetcher<ToDo> {
@Transactional
override fun get(env: DataFetchingEnvironment): ToDo {
val title = env.getArgument<String>("title")!!
val username = env.getArgument<String>("author")!!
val author = authorRepository.findOrCreate(username) (3)
val toDo = ToDo(title, author.id!!)
return toDoRepository.save(toDo) (4)
}
}| 1 | Use jakarta.inject.Singleton to designate a class as a singleton. |
| 2 | Use constructor injection to inject a bean of type ToDoRepository. |
| 3 | Find the existing author or create a new one. |
| 4 | Persist the new ToDo. |
And CompleteToDoDataFetcher to mark ToDos as complete:
src/main/kotlin/example/micronaut/CompleteToDoDataFetcher.kt
package example.micronaut
import graphql.schema.DataFetcher
import graphql.schema.DataFetchingEnvironment
import jakarta.inject.Singleton
@Singleton (1)
class CompleteToDoDataFetcher(
private val toDoRepository: ToDoRepository (2)
) : DataFetcher<Boolean> {
override fun get(env: DataFetchingEnvironment): Boolean {
val id = env.getArgument<String>("id")!!.toLong()
return toDoRepository
.findById(id) (3)
.map { todo -> setCompletedAndUpdate(todo!!) }
.orElse(false)
}
private fun setCompletedAndUpdate(todo: ToDo): Boolean {
todo.completed = true (4)
toDoRepository.update(todo) (5)
return true
}
}| 1 | Use jakarta.inject.Singleton to designate a class as a singleton. |
| 2 | Use constructor injection to inject a bean of type ToDoRepository. |
| 3 | Find the existing ToDo based on its id. |
| 4 | If found, set completed. |
| 5 | And update the version in the database. |
6.2.3. Wiring
GraphQL allows data to be fetched on demand. In this example, a user may request a list of ToDos, but not require the author to be populated. A method is required to optionally load Authors based on their ID.
To do this, register a DataLoader that finds authors based on a collection of ids:
src/main/kotlin/example/micronaut/AuthorDataLoader.kt
package example.micronaut
import io.micronaut.scheduling.TaskExecutors
import jakarta.inject.Named
import jakarta.inject.Singleton
import org.dataloader.MappedBatchLoader
import java.util.concurrent.CompletableFuture
import java.util.concurrent.CompletionStage
import java.util.concurrent.ExecutorService
@Singleton (1)
class AuthorDataLoader(
private val authorRepository: AuthorRepository,
@Named(TaskExecutors.BLOCKING) val executor: ExecutorService (2)
) : MappedBatchLoader<Long, Author> {
override fun load(keys: MutableSet<Long>): CompletionStage<Map<Long, Author>> =
CompletableFuture.supplyAsync({
authorRepository
.findByIdIn(keys.toList())
.associateBy { it.id!! }
}, executor)
}| 1 | Use jakarta.inject.Singleton to designate a class as a singleton. |
| 2 | Inject the IO executor service. |
This is registered in the DataLoaderRegistry under the key author
src/main/kotlin/example/micronaut/DataLoaderRegistryFactory.kt
package example.micronaut
import io.micronaut.context.annotation.Factory
import io.micronaut.runtime.http.scope.RequestScope
import org.dataloader.DataLoader
import org.dataloader.DataLoaderRegistry
import org.slf4j.LoggerFactory
@Factory (1)
class DataLoaderRegistryFactory {
companion object {
private val LOG = LoggerFactory.getLogger(DataLoaderRegistryFactory::class.java)
}
@Suppress("unused")
@RequestScope (2)
fun dataLoaderRegistry(authorDataLoader: AuthorDataLoader): DataLoaderRegistry {
val dataLoaderRegistry = DataLoaderRegistry()
dataLoaderRegistry.register(
"author",
DataLoader.newMappedDataLoader(authorDataLoader)
) (3)
LOG.trace("Created new data loader registry")
return dataLoaderRegistry
}
}| 1 | A class annotated with the @Factory annotated is a factory. It provides one or more methods annotated with a bean scope annotation (e.g. @Singleton). Read more about Bean factories. |
| 2 | This registry has request scope, so a new one will be created for every request. |
| 3 | Register the AuthorDataLoader whenever the loader for "author" is requested. |
Add an AuthorDataFetcher which requests and uses this loader to populate a ToDo if the author when required.
src/main/kotlin/example/micronaut/AuthorDataFetcher.kt
package example.micronaut
import graphql.schema.DataFetcher
import graphql.schema.DataFetchingEnvironment
import jakarta.inject.Singleton
import java.util.concurrent.CompletionStage
@Singleton (1)
class AuthorDataFetcher : DataFetcher<CompletionStage<Author>> {
override fun get(environment: DataFetchingEnvironment): CompletionStage<Author> {
val toDo: ToDo = environment.getSource()!!
val authorDataLoader = environment.getDataLoader<Long, Author>("author")!! (2)
return authorDataLoader.load(toDo.authorId)
}
}| 1 | Use jakarta.inject.Singleton to designate a class as a singleton. |
| 2 | Uses the author data loader defined above in the Factory. |
6.3. GraphQL Factory
Finally, create a factory class that will bind the GraphQL schema to the code, types and fetchers.
src/main/kotlin/example/micronaut/GraphQLFactory.kt
package example.micronaut
import graphql.GraphQL
import graphql.schema.idl.*
import graphql.schema.idl.errors.SchemaMissingError
import io.micronaut.context.annotation.Factory
import io.micronaut.core.io.ResourceResolver
import jakarta.inject.Singleton
import java.io.BufferedReader
import java.io.InputStreamReader
@Factory (1)
class GraphQLFactory {
@Singleton (2)
fun graphQL(
resourceResolver: ResourceResolver,
toDosDataFetcher: ToDosDataFetcher,
createToDoDataFetcher: CreateToDoDataFetcher,
completeToDoDataFetcher: CompleteToDoDataFetcher,
authorDataFetcher: AuthorDataFetcher
): GraphQL {
val schemaParser = SchemaParser()
val schemaGenerator = SchemaGenerator()
// Load the schema
val schemaDefinition = resourceResolver
.getResourceAsStream("classpath:schema.graphqls")
.orElseThrow { SchemaMissingError() }
// Parse the schema and merge it into a type registry
val typeRegistry = TypeDefinitionRegistry()
typeRegistry.merge(schemaParser.parse(BufferedReader(InputStreamReader(schemaDefinition))))
// Create the runtime wiring.
val runtimeWiring = RuntimeWiring.newRuntimeWiring()
.type("Query") { typeWiring: TypeRuntimeWiring.Builder -> (3)
typeWiring
.dataFetcher("toDos", toDosDataFetcher)
}
.type("Mutation") { typeWiring: TypeRuntimeWiring.Builder -> (4)
typeWiring
.dataFetcher("createToDo", createToDoDataFetcher)
.dataFetcher("completeToDo", completeToDoDataFetcher)
}
.type("ToDo") { typeWiring: TypeRuntimeWiring.Builder -> (5)
typeWiring
.dataFetcher("author", authorDataFetcher)
}
.build()
// Create the executable schema.
val graphQLSchema = schemaGenerator.makeExecutableSchema(typeRegistry, runtimeWiring)
// Return the GraphQL bean.
return GraphQL.newGraphQL(graphQLSchema).build()
}
}| 1 | A class annotated with the @Factory annotated is a factory. It provides one or more methods annotated with a bean scope annotation (e.g. @Singleton). Read more about Bean factories. |
| 2 | Use jakarta.inject.Singleton to designate a class as a singleton. |
| 3 | Wire up the query behavior. |
| 4 | Wire up each mutators. |
| 5 | Wire up how to populate a ToDo with authors if they are requested. |
7. Test Resources
When the application is started locally — either under test or by running the application — resolution of the datasource URL is detected and the Test Resources service will start a local PostgreSQL docker container, and inject the properties required to use this as the datasource.
For more information, see the JDBC section of the Test Resources documentation.
8. Running the Application
To run the application, use the ./mvnw mn:run command, which starts the application on port 8080.
When the application first runs, you will see in the logs that the migrations have been performed.
9. Test the application
9.1. Manual smoke tests
Formulate a GraphQL query to retrieve all the current ToDos (there will be none to start with)
Query
query {
toDos {
title,
completed,
author {
username
}
}
}Run the following cURL request:
curl -X POST 'http://localhost:8080/graphql' \
-H 'content-type: application/json' \
--data-binary '{"query":"{ toDos { title, completed, author { username } } }"}'Response
{"data":{"toDos":[]}}Create a ToDo, by issuing a mutation query and return the ID of the newly created ToDo:
GraphQL Query
mutation {
createToDo(title: "Create GraphQL Guide", author: "Tim Yates") {
id
}
}Which translates to this cURL command:
curl -X POST 'http://localhost:8080/graphql' \
-H 'content-type: application/json' \
--data-binary '{"query":"mutation { createToDo(title:\"Create GraphQL Guide\", author:\"Tim Yates\") { id } }"}'Response
{"data":{"createToDo":{"id":"1"}}}This new ToDo then appears in the list of all ToDos with completed set to false:
curl -X POST 'http://localhost:8080/graphql' \
-H 'content-type: application/json' \
--data-binary '{"query":"{ toDos { title, completed, author { username } } }"}'Response
{"data":{"toDos":[{"title":"Create GraphQL Guide","completed":false,"author":{"username":"Tim Yates"}}]}}Mark it as completed by using this query with the ID from above:
GraphQL query
mutation {
completeToDo(id: 1)
}curl -X POST 'http://localhost:8080/graphql' \
-H 'content-type: application/json' \
--data-binary '{"query":"mutation { completeToDo(id: 1) }"}'Response
{"data":{"completeToDo":true}}Check this has been persisted in our model:
Query
curl -X POST 'http://localhost:8080/graphql' \
-H 'content-type: application/json' \
--data-binary '{"query":"{ toDos { title, completed } }"}'Response
{"data":{"toDos":[{"title":"Create GraphQL Guide","completed":true}]}}9.2. Automated tests
For testing the application use the Micronaut HTTP Client to send a POST request to the /graphql endpoint.
Create the following class:
src/test/kotlin/example/micronaut/GraphQLControllerTest.kt
package example.micronaut
import io.micronaut.core.type.Argument
import io.micronaut.http.HttpRequest
import io.micronaut.http.HttpResponse
import io.micronaut.http.HttpStatus
import io.micronaut.http.client.HttpClient
import io.micronaut.http.client.annotation.Client
import io.micronaut.test.extensions.junit5.annotation.MicronautTest
import jakarta.inject.Inject
import org.junit.jupiter.api.Assertions
import org.junit.jupiter.api.Assertions.assertEquals
import org.junit.jupiter.api.Assertions.assertTrue
import org.junit.jupiter.api.Assertions.assertFalse
import org.junit.jupiter.api.Test
@MicronautTest (1)
internal class GraphQLControllerTest(@Client("/") val client: HttpClient) { (2)
@Test
fun testGraphQLController() {
// when:
var todos = allTodos
// then:
assertTrue(todos.isEmpty())
// when:
val id = createToDo("Test GraphQL", "Tim Yates")
// then: (check it's a UUID)
assertEquals(1, id)
// when:
todos = allTodos
// then:
assertEquals(1, todos.size)
var todo = todos[0]
assertEquals("Test GraphQL", todo["title"])
assertFalse(java.lang.Boolean.parseBoolean(todo["completed"].toString()))
assertEquals(
"Tim Yates",
(todo["author"] as Map<*, *>?)!!["username"]
)
// when:
val completed = markAsCompleted(id)
// then:
assertTrue(completed)
// when:
todos = allTodos
// then:
assertEquals(1, todos.size)
todo = todos[0]
assertEquals("Test GraphQL", todo["title"])
assertTrue(java.lang.Boolean.parseBoolean(todo["completed"].toString()))
assertEquals(
"Tim Yates",
(todo["author"] as Map<*, *>?)!!["username"]
)
}
private fun fetch(query: String): HttpResponse<Map<String, Any>> {
val request: HttpRequest<String> = HttpRequest.POST("/graphql", query)
val response = client.toBlocking().exchange(
request, Argument.mapOf(Argument.STRING, Argument.OBJECT_ARGUMENT)
)
assertEquals(HttpStatus.OK, response.status())
Assertions.assertNotNull(response.body())
return response
}
private val allTodos: List<Map<String, Any>>
get() {
val query = "{\"query\":\"query { toDos { title, completed, author { id, username } } }\"}"
val response = fetch(query)
return (response.body.get()["data"] as Map<*, *>)["toDos"] as List<Map<String, Any>>
}
private fun createToDo(title: String, author: String): Long {
val query =
"{\"query\": \"mutation { createToDo(title: \\\"$title\\\", author: \\\"$author\\\") { id } }\" }"
val response = fetch(query)
return ((response.body.get().get("data") as Map<*, *>)["createToDo"] as Map<*, *>?)!!["id"].toString().toLong()
}
private fun markAsCompleted(id: Long): Boolean {
val query = "{\"query\": \"mutation { completeToDo(id: \\\"$id\\\") }\" }"
val response = fetch(query)
return (response.body.get()["data"] as Map<String, Any>)["completeToDo"] as Boolean
}
}| 1 | Annotate the class with @MicronautTest so the Micronaut framework will initialize the application context and the embedded server. More info. |
| 2 | Inject the HttpClient bean and point it to the embedded server. |
To run the tests:
./mvnw test10. GraphiQL
As an extra feature that will help during development, you can enable GraphiQL. GraphiQL is the GraphQL integrated development environment, and it executes GraphQL queries.
It should only be used for development, so it’s not enabled by default. Add the following configuration to enable it:
src/main/resources/application.properties
graphql.graphiql.enabled=trueStart the application again and open http://localhost:8080/graphiql in a browser. GraphQL queries can be executed with integrated auto-completion:
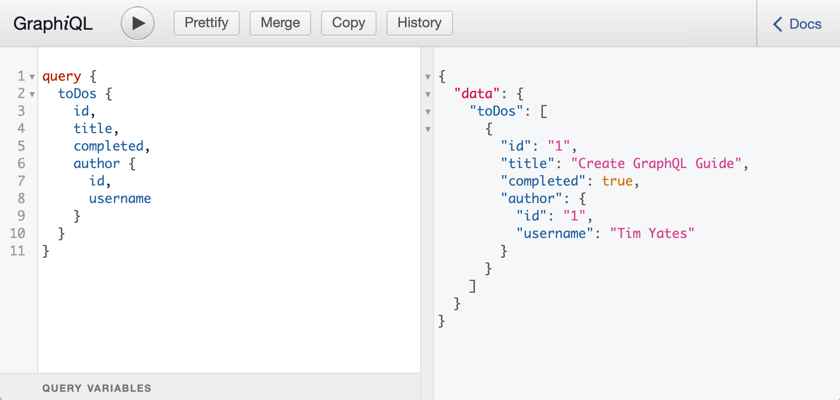
11. Generate a Micronaut Application Native Executable with GraalVM
We will use GraalVM, an advanced JDK with ahead-of-time Native Image compilation, to generate a native executable of this Micronaut application.
Compiling Micronaut applications ahead of time with GraalVM significantly improves startup time and reduces the memory footprint of JVM-based applications.
Only Java and Kotlin projects support using GraalVM’s native-image tool. Groovy relies heavily on reflection, which is only partially supported by GraalVM.
|
11.1. GraalVM Installation
Java 21
sdk install java 21.0.5-graalFor installation on Windows, or for a manual installation on Linux or Mac, see the GraalVM Getting Started documentation.
The previous command installs Oracle GraalVM, which is free to use in production and free to redistribute, at no cost, under the GraalVM Free Terms and Conditions.
Alternatively, you can use the GraalVM Community Edition:
Java 21
sdk install java 21.0.2-graalce11.2. Native Executable Generation
To generate a native executable using Maven, run:
./mvnw package -Dpackaging=native-imageThe native executable is created in the target directory and can be run with target/micronautguide.
It is possible to customize the name of the native executable or pass additional build arguments using the Maven plugin for GraalVM Native Image building. Declare the plugin as following:
pom.xml
<plugin>
<groupId>org.graalvm.buildtools</groupId>
<artifactId>native-maven-plugin</artifactId>
<version>0.11.3</version>
<configuration>
(1)
<imageName>mn-graalvm-application</imageName>
<buildArgs>
(2)
<buildArg>-Ob</buildArg>
</buildArgs>
</configuration>
</plugin>| 1 | The native executable name will now be mn-graalvm-application. |
| 2 | It is possible to pass extra build arguments to native-image. For example, -Ob enables the quick build mode. |
Start the native executable and execute the same cURL request as before. You can also use the included GraphiQL browser to execute the queries.
12. Next Steps
Take a look at the Micronaut GraphQL documentation.
13. Help with the Micronaut Framework
The Micronaut Foundation sponsored the creation of this Guide. A variety of consulting and support services are available.
14. License
| All guides are released with an Apache license 2.0 license for the code and a Creative Commons Attribution 4.0 license for the writing and media (images…). |